










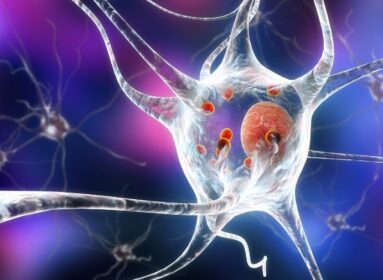


Neural networks enable learning of error correction strategies for computers based on quantum physics
Quantum computers could solve complex tasks that are beyond the capabilities of conventional computers. However, the quantum states are extremely sensitive to constant interference from their environment. The plan is to combat this using active protection based on quantum error correction. Florian Marquardt, Director at the Max Planck Institute for the Science of Light, and his team have now presented a quantum error correction system that is capable of learning thanks to artificial intelligence. In 2016, the computer program AlphaGo won four out of five games of Go against the world’s best human player. Given that a game of Go has more combinations of moves than there are estimated to be atoms in the universe, this required more than just sheer processing power. Rather, AlphaGo used artificial neural networks, which can recognize visual patterns and are even capable of learning. Unlike a human, the program was able to practice hundreds of thousands of games in a short time, eventually surpassing the best human player. Now, the Erlangen-based researchers are using neural networks of this kind to develop error-correction learning for a quantum computer. Artificial neural networks are computer programs that mimic the behaviour of interconnected nerve cells (neurons) — in the case of the research in Erlangen, around two thousand artificial neurons relate to one another. “We take the latest ideas from computer science and apply them to physical systems,” explains Florian Marquardt. “By doing so, we profit from rapid progress in the area of artificial intelligence.”
The first area of application are quantum computers, as shown by the recent paper, which includes a significant contribution by Thomas Fösel, a doctoral student at the Max Planck Institute in Erlangen. In the paper, the team demonstrates that artificial neural networks with an AlphaGo-inspired architecture are capable of learning — for themselves — how to perform a task that will be essential for the operation of future quantum computers: quantum error correction. There is even the prospect that, with enough training, this approach will outstrip other error-correction strategies. To understand what it involves, you need to look at the way quantum computers work. The basis for quantum information is the quantum bit, or qubit. Unlike conventional digital bits, a qubit can adopt not only the two states zero and one, but also superpositions of both states. In a quantum computer’s processor, there are even multiple qubits superimposed as part of a joint state. This entanglement explains the tremendous processing power of quantum computers when it comes to solving certain complex tasks at which conventional computers are doomed to fail. The downside is that quantum information is highly sensitive to noise from its environment. This and other peculiarities of the quantum world mean that quantum information needs regular repairs — that is, quantum error correction. However, the operations that this requires are not only complex but must also leave the quantum information itself intact.

“You can imagine the elements of a quantum computer as being just like a Go board,” says Marquardt, getting to the core idea behind his project. The qubits are distributed across the board like pieces. However, there are certain key differences from a conventional game of Go: all the pieces are already distributed around the board, and each of them is white on one side and black on the other. One colour corresponds to the state zero, the other to one, and a move in a game of quantum Go involves turning pieces over. According to the rules of the quantum world, the pieces can also adopt grey mixed colours, which represent the superposition and entanglement of quantum states.
When it comes to playing the game, a player — we’ll call her Alice — makes moves that are intended to preserve a pattern representing a certain quantum state. These are the quantum error correction operations. In the meantime, her opponent does everything they can to destroy the pattern. This represents the constant noise from the plethora of interference that real qubits experience from their environment. In addition, a game of quantum Go is made especially difficult by a peculiar quantum rule: Alice is not allowed to look at the board during the game. Any glimpse that reveals the state of the qubit pieces to her destroys the sensitive quantum state that the game is currently occupying. The question is: how can she make the right moves despite this?
Auxiliary qubits reveal defects in the quantum computer. In quantum computers, this problem is solved by positioning additional qubits between the qubits that store the actual quantum information. Occasional measurements can be taken to monitor the state of these auxiliary qubits, allowing the quantum computer’s controller to identify where faults lie and to perform correction operations on the information-carrying qubits in those areas. In our game of quantum Go, the auxiliary qubits would be represented by additional pieces distributed between the actual game pieces. Alice is allowed to look occasionally, but only at these auxiliary pieces.
In the Erlangen researchers’ work, Alice’s role is performed by artificial neural networks. The idea is that, through training, the networks will become so good at this role that they can even outstrip correction strategies devised by intelligent human minds. However, when the team studied an example involving five simulated qubits, a number that is still manageable for conventional computers, they were able to show that one artificial neural network alone is not enough. As the network can only gather small amounts of information about the state of the quantum bits, or rather the game of quantum Go, it never gets beyond the stage of random trial and error. Ultimately, these attempts destroy the quantum state instead of restoring it.
The solution comes in the form of an additional neural network that acts as a teacher to the first network. With its prior knowledge of the quantum computer that is to be controlled, this teacher network is able to train the other network — its student — and thus to guide its attempts towards successful quantum correction. First, however, the teacher network itself needs to learn enough about the quantum computer or the component of it that is to be controlled.
Are trained using a reward system, just like their natural models. The actual reward is provided for successfully restoring the original quantum state by quantum error correction. “However, if only the achievement of this long-term aim gave a reward, it would come at too late a stage in the numerous correction attempts,” Marquardt explains. The Erlangen-based researchers have therefore developed a reward system that, even at the training stage, incentivizes the teacher neural network to adopt a promising strategy. In the game of quantum Go, this reward system would provide Alice with an indication of the general state of the game at a given time without giving away the details.
The student network can surpass its teacher through its own actions
“Our first aim was for the teacher network to learn to perform successful quantum error correction operations without further human assistance,” says Marquardt. Unlike the school student network, the teacher network can do this based not only on measurement results but also on the overall quantum state of the computer. The student network trained by the teacher network will then be equally good at first but can become even better through its own actions.
In addition to error correction in quantum computers, Florian Marquardt envisages other applications for artificial intelligence. In his opinion, physics offers many systems that could benefit from the use of pattern recognition by artificial neural networks.
Source: Max-Planck-Gesellschaft.





































{kind=link}
Comments are closed.